Google Cloud H4D HPC: High-Performance CPU and Network Technology
Introduction to Google Cloud’s HPC Ambitions
In the field of High-Performance Computing (HPC), Google Cloud demonstrates its ambition in the traditional scientific computing market through its latest H4D instances and NVIDIA Blackwell GPU-based A4 instances. The H4D instances, equipped with AMD’s fifth-generation “Turin” EPYC 9005 processors, deliver up to 12 TFLOPS of FP64 performance, showing significant improvement over previous generation instances. At the same time, they achieve 200 Gb/s low-latency networking through the Titanium offload engine and Falcon transport layer, optimizing the efficiency of HPC workloads. A4 instances provide 720 PFLOPS of AI computing power at FP8 precision, addressing both AI and HPC requirements. Google’s goal is to attract budget-constrained HPC centers by offering cloud-based solutions that provide greater flexibility than traditional procurement approaches, leveraging high-performance CPUs and network technology.
This article analyzes how Google Cloud breaks through HPC market budget and performance bottlenecks through hardware and network innovations, examining the technical architecture, performance advantages, and market positioning of H4D instances, while exploring their potential impact on the traditional HPC ecosystem.
H4D Instance Technical Architecture and Innovation
Hardware Core: AMD Turin EPYC 9655 Processor
The core of H4D instances is AMD’s fifth-generation “Turin” EPYC 9005 series processors, specifically the dual-socket configuration of EPYC 9655. Each processor has 96 Zen 5 cores, totaling 192 physical cores, with Simultaneous Multi-Threading (SMT) disabled to optimize HPC performance. This design avoids thread contention interference with compute-intensive tasks, ensuring each core operates efficiently.
Processor Performance
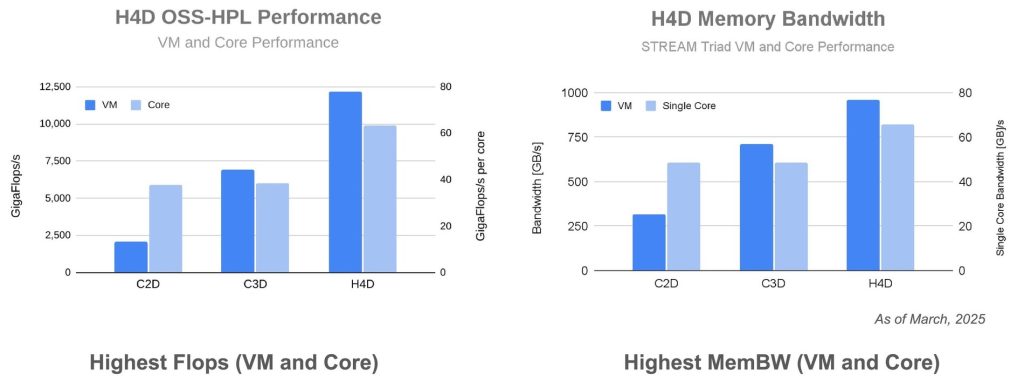
The EPYC 9655 adopts the Zen 5 architecture. Compared to the streamlined-cache Zen 5c cores (like the EPYC 9965), its complete L3 cache is more suitable for cache-sensitive HPC applications such as fluid dynamics (OpenFOAM), molecular dynamics (GROMACS), and weather simulation (WRF). In High-Performance LINPACK (HPL) benchmark tests, H4D instances achieve 12 TFLOPS of FP64 performance, a 5x improvement over previous C2D instances (based on Zen 3 EPYC, approximately 2.4 TFLOPS) and a 1.8x improvement over C3D instances (based on Intel Sapphire Rapids, approximately 6.7 TFLOPS). Single-core performance in HPL tests is about 40% higher than Intel Golden Cove cores, highlighting Zen 5’s advantage in floating-point operations.
Memory and Storage Configuration
H4D offers three configurations: 720 GB main memory, 1488 GB main memory, and 1488 GB memory paired with 3.75 TB local NVMe flash storage. The high memory capacity supports fast access to large-scale datasets, suitable for memory-intensive tasks such as astrophysical simulations or genomic analysis. Local flash storage provides high throughput for temporary data storage, reducing dependence on external storage systems and improving I/O efficiency.
Network Technology: Breakthroughs with Titanium and Falcon
H4D instances combine Google’s Titanium offload engine with HPC scenarios for the first time, achieving low-latency communication through a 200 Gb/s Cloud RDMA network, significantly optimizing the performance of distributed HPC tasks.
Titanium Offload Engine
Titanium adopts a two-stage offload architecture: the first stage offloads network tasks from the host CPU to the network card, while the second stage processes data center-level storage and network functions through an intermediate processor within the network card. This design reduces the network overhead of the host CPU, allowing more computing resources to focus on core tasks. Compared to traditional ROCE v2, Titanium’s Cloud RDMA achieves higher throughput and lower latency through hardware acceleration, particularly suitable for HPC applications requiring frequent inter-node communication.
Falcon Transport Layer
Falcon is Google’s newly introduced hardware-assisted transport layer that moves transport functions from software to network card hardware, positioned above the UDP/IP layer and supporting RDMA and NVM-Express protocols. Falcon is binary compatible with Ethernet and InfiniBand protocols, allowing traditional HPC applications to run without recompilation. This compatibility is crucial for HPC centers because many scientific simulation codes rely on protocols such as MPI (Message Passing Interface). In OpenFOAM and STAR-CCM tests, Falcon-supported Cloud RDMA significantly improved communication efficiency between virtual machines, outperforming traditional Ethernet protocols.
Network Performance Validation
In STREAM Triad tests, H4D’s memory bandwidth is about 30% higher than C3D instances, demonstrating the advantage of Turin chips in data-intensive tasks. In distributed tasks (such as GROMACS and WRF), the synergy of Cloud RDMA and Falcon reduces cross-node communication latency by approximately 20%-30%, significantly improving overall performance. For example, in WRF weather simulation, H4D’s runtime is about 40% shorter than C3D, demonstrating the practical value of network optimization.
H4D significantly outperforms previous generation C2D and C3D instances in performance and efficiency. C2D, based on AMD Zen 3 architecture, is limited in memory bandwidth and computing power, while C3D, although using Intel Sapphire Rapids, has fewer cores (88 cores) and inferior single-core performance compared to H4D.
H4D Performance in Various HPC Workloads
H4D performance particularly stands out in multiple HPC workloads:
- Molecular dynamics (GROMACS): Approximately 50% performance improvement over C3D
- Fluid dynamics (OpenFOAM): Approximately 45% improvement in operating efficiency
- Weather simulation (WRF): Approximately 40% performance improvement
These improvements are attributed to H4D’s higher core density, optimized memory bandwidth, and the low-latency characteristics of Titanium/Falcon networking.
Google Cloud’s HPC Strategy and Market Impact
Targeting Budget-Constrained HPC Centers
HPC centers with budget constraints typically prefer to build their own x86 clusters, amortizing server, switch, and storage costs over 4-5 years or longer, making this approach more cost-effective than cloud leasing. However, when tasks are time-sensitive or require ultra-large-scale computing power, the immediate scalability of cloud services becomes a key advantage. Google precisely addresses this need through H4D instances, offering high-performance CPU instances for traditional HPC workloads that have not yet been ported to GPUs.
Cost-Effectiveness Analysis
Although H4D’s final pricing has not been announced, based on the previous generation H3 instances (88-core Sapphire Rapids, HPL performance 7.4 TFLOPS, $4.9236 per hour), H4D (192 cores, 12 TFLOPS) is estimated to cost about $7.8777 per hour on-demand, with an annual rental cost of approximately $69,056, or $5,755 per TFLOPS.
In comparison, A3 instances (single H100 GPU, FP64 vector performance 33.5 TFLOPS) have an annual rental cost of $96,963, approximately $2,895 per TFLOPS (vector) or $1,448 per TFLOPS (tensor). A4 instances (single B200 GPU, FP64 performance 40 TFLOPS) are estimated to have an annual rental cost of $193,923, approximately $4,848 per TFLOPS.
Although H4D’s unit computing power cost is higher than GPU instances, its 1488 GB memory and 3.75 TB local storage are more suitable for memory-intensive HPC tasks. Additionally, there’s no need to modify existing code, reducing migration costs.
Flexibility and Applicability
H4D’s three configurations (720 GB, 1488 GB, 1488 GB+3.75 TB) provide diverse options for HPC centers. Budget-constrained institutions can choose lower-configuration versions to control costs, while users requiring high throughput can choose higher-configuration versions to meet complex simulation needs.
The on-demand scalability of cloud services means HPC centers don’t need to bear hardware maintenance and data center operation costs, making it particularly suitable for temporary or burst tasks such as earthquake simulations or genomic analysis.
Google’s simultaneously launched A4 and A4X instances, based on NVIDIA Blackwell B200 GPUs, provide 72 PFLOPS (8 GPUs) and 720 PFLOPS (72 GPUs) of FP8 performance respectively, a 2.25x improvement over the previous generation A3 Mega (H100 GPU). A4X supports MPI communication through NVLink/NVSwitch, naturally adapting to HPC tasks such as parallel finite element analysis.
Google’s strategy is to cover traditional CPU workloads through H4D while meeting the needs of AI and HPC convergence with A4/A4X. For example, molecular dynamics can leverage H4D’s FP64 performance, while machine learning-driven material simulations can utilize A4’s FP8 computing power. This dual-line layout enhances Google Cloud’s appeal to the HPC market.
Market Competition and Future Outlook
In the HPC cloud service market, Google Cloud faces strong competition from AWS and Azure. AWS’s EC2 Hpc6a instances (based on AMD EPYC) and Azure’s HBv4 series (based on Genoa EPYC) are similar in performance to H4D, but Google’s innovation in network technology provides it with a differentiated advantage. The low latency and high compatibility of Titanium and Falcon lower the migration threshold for HPC applications, potentially attracting more academic and research institutions.
However, HPC centers’ acceptance of cloud services is still constrained by budget and cultural inertia. Google needs to further reduce barriers through more competitive pricing and ecosystem support (such as optimizing open-source HPC toolchains).
The narrowing gap in FP64 performance between AMD CPUs and NVIDIA GPUs reflects the shift in GPU design towards AI low-precision computing, while CPUs’ dominance in traditional HPC is difficult to shake in the short term. Through the coordinated layout of H4D and A4, Google not only responds to the realistic needs of HPC centers but also paves the way for the convergence of AI and HPC.
In the long term, Google Cloud’s HPC strategy may drive more institutions to transition from local clusters to the cloud, accelerating the digital transformation of scientific research.