Comparison of AI Model Performance of Rockchip Mainstream SoCs such as RK3588, RK3576, RK3568, RV1126, etc.
As a leading domestic AIoT SoC chip supplier, Rockchip’s product line covers application requirements across multiple domains, with excellent performance particularly in AI model capabilities. Its technological foresight, rich product lineup, mature AI toolchain, and extensive AI example library have driven the development and application of AI technology. This article will deeply analyze the AI model performance of Rockchip’s mainstream SoCs, comparing their performance across different models, to provide a preliminary understanding and help you choose the appropriate chip for your projects.
Technological Foresight: Integration of Independent NPU
Rockchip is one of the earliest manufacturers in the industry to integrate independent NPU (Neural Processing Unit) into SoC (System on Chip). This forward-looking technological layout gives Rockchip’s SoC products significant performance advantages when processing AI-related tasks. The independent NPU design specifically targets AI computing tasks, such as inference and training of deep learning models, providing efficient computing power and optimized energy efficiency. This technological layout not only enhances the AI processing capabilities of SoCs but also sets a benchmark for the industry’s technological development.
Rich Product Line: Meeting Diverse Performance Needs
Rockchip’s AI processor series includes multiple products such as RK3566, RK3568, RK3562, RK3576, RK3588, RV1109, RV1126, RV1108, each optimized for different markets and application scenarios. For example, RK3588 as a flagship product adopts advanced process technology and high-performance CPU and GPU configurations, suitable for high-end AI application scenarios such as intelligent video analysis and edge computing. Products like RV1109 focus more on cost-effectiveness, suitable for entry-level AI applications such as smart home devices and simple security monitoring. This rich product line layout enables Rockchip to meet the needs of different customers from low-end to high-end, providing strong hardware support for various AI applications.
Mature AI Toolchain: Simplifying Development Process
Rockchip’s layout in AI toolchain equally reflects its profound understanding of industry development. The launch of AI development tools such as RKNN-Toolkit and Rock-X SDK has greatly simplified the development and deployment process of AI models. These tools provide functions such as model conversion, quantization, and optimization, making it easier for developers to deploy trained AI models on Rockchip’s SoC platforms. Additionally, these tools support multiple deep learning frameworks such as TensorFlow and Caffe, further lowering the development threshold and accelerating the application and popularization of AI technology.
Rich AI Example Library: Foundation for Rapid Implementation
The AI example library provided by Rockchip contains various pre-trained models covering multiple fields such as image recognition, speech recognition, and video analysis. These example libraries not only provide learning and reference resources for developers but also offer convenience for rapid implementation of AI applications. Developers can build on these example libraries for secondary development, quickly creating AI applications that meet specific needs, greatly shortening the cycle from product design to market launch.
Performance Comparative Analysis
Model Performance Benchmark (FPS)
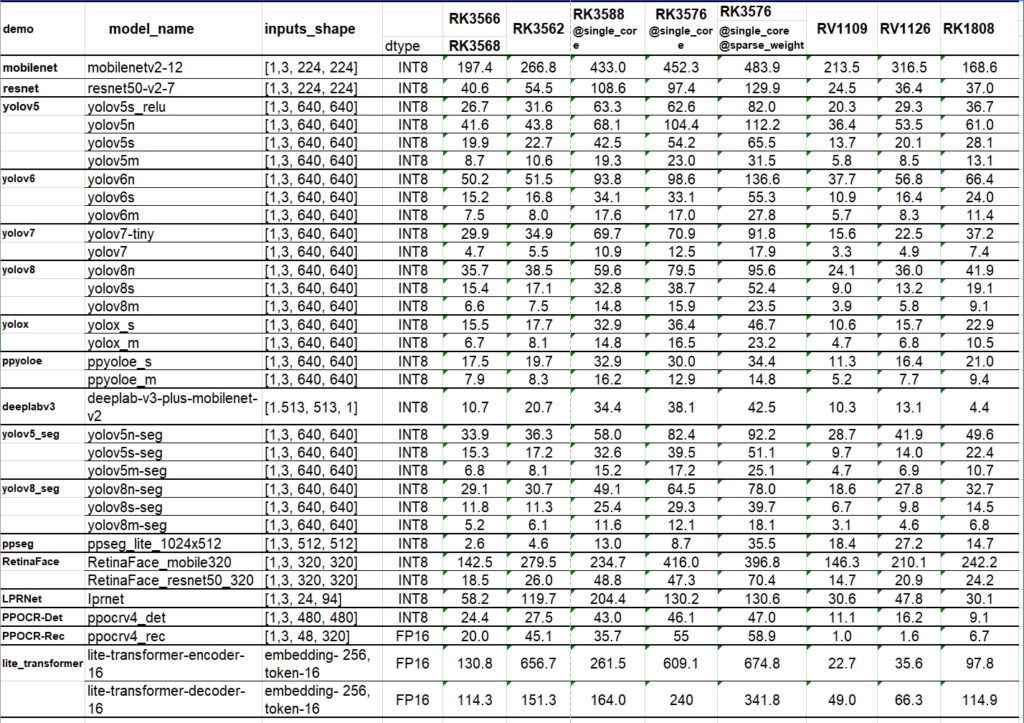
Through specific performance benchmark data, we can compare the performance of different Rockchip SoCs in processing AI models. Taking mobilenet as an example, RK3588 can achieve 452.3 FPS in single-core state, while RK3576 reaches 483.9 FPS, demonstrating RK3588’s powerful performance in processing AI models. In the resnet50-v2-7 model, RK3588’s single-core performance is 97.4 FPS, while RK3576 is 129.9 FPS, also proving RK3588’s advantage in high-performance AI processing.
In the yolov5 series models, we can see that RK3588 demonstrates excellent performance when processing different versions of yolov5, whether in single-core or sparse weight core state. For example, in the yolov5s model, RK3588’s single-core performance is 54.2 FPS, while RK3576 is 65.5 FPS. This indicates that RK3588 has higher efficiency and accuracy when processing complex object detection tasks.
In the yolov6 and yolov7 series models, RK3588 also maintains its high-performance advantage. For example, in the yolov6n model, RK3588’s single-core performance is 98.6 FPS, while RK3576 is 136.6 FPS. This further confirms RK3588’s capability in handling more demanding AI tasks.
In models such as yolov8, yolox, ppyoloe, and deeplabv3, RK3588’s performance is equally outstanding. Especially in the deeplab-v3-plus-mobilenet-v2 model, RK3588’s single-core performance reaches 38.1 FPS, while RK3576 is 42.5 FPS.
In models such as RetinaFace and LPRNet, RK3588’s performance is also noteworthy. In the RetinaFace_mobile320 model, RK3588’s single-core performance is 416.0 FPS, while RK3576 is 396.8 FPS. This demonstrates RK3588’s efficiency in handling challenging tasks such as face recognition.
Conclusion
Rockchip’s SoC product line performs excellently in AI model performance, especially RK3588 which demonstrates powerful processing capabilities across multiple models. This is due not only to Rockchip’s technical accumulation and innovation in the AI field but also to its mature AI toolchain and rich example library. The diverse product line can meet functional requirements for different scenarios. With the continuous advancement of AI technology, Rockchip’s SoC products are expected to play a greater role in the future AIoT market.

Note: The performance data in this article is collected based on the maximum NPU frequency of each platform. These performance data calculate the time consumption of model inference, not including time-consuming preprocessing and post-processing. RK3576 with sparse weights refers to performance when model sparse weights are enabled. Note that models with sparse weights (through kernels) should be able to improve performance, but accuracy may decrease depending on the model.