Google’s 7th Gens TPU: Ironwood Ready for AI Inference Tasks
Introduction
At the 2025 Google Cloud Next conference, Google officially unveiled its seventh-generation Tensor Processing Unit (TPU), codenamed “Ironwood.”
As Google’s most powerful AI chip to date, Ironwood is specifically designed for AI inference tasks, marking the transition of AI technology from traditional “reactive” models to “proactive” intelligent agents. Compared to the first-generation TPU from 2018, Ironwood’s inference performance has improved by 3,600 times, with efficiency increased by 29 times.
Each chip is equipped with 192GB of high-bandwidth memory (HBM), delivers a peak computing power of 4,614 TFLOPs, and supports 1.2Tbps of chip-to-chip interconnect (ICI) bandwidth.
Compared to the previous generation Trillium, its energy efficiency has doubled. The highest configuration cluster of 9,216 chips offers a total computing power of 42.5 Exaflops, exceeding the world’s largest supercomputer El Capitan by 24 times. Ironwood is expected to be available to customers through Google Cloud later this year, providing developers with unprecedented AI computing capabilities.

Ironwood’s Technical Architecture and Innovation
Ironwood is Google’s seventh-generation TPU built on a 5-nanometer process, with hardware specifications that set a new benchmark in the AI chip sector.
Each chip is equipped with 192GB of high-bandwidth memory (HBM), delivers a peak computing power of 4,614 TFLOPs, and enables efficient distributed computing through 1.2Tbps of chip-to-chip interconnect (ICI) bandwidth.
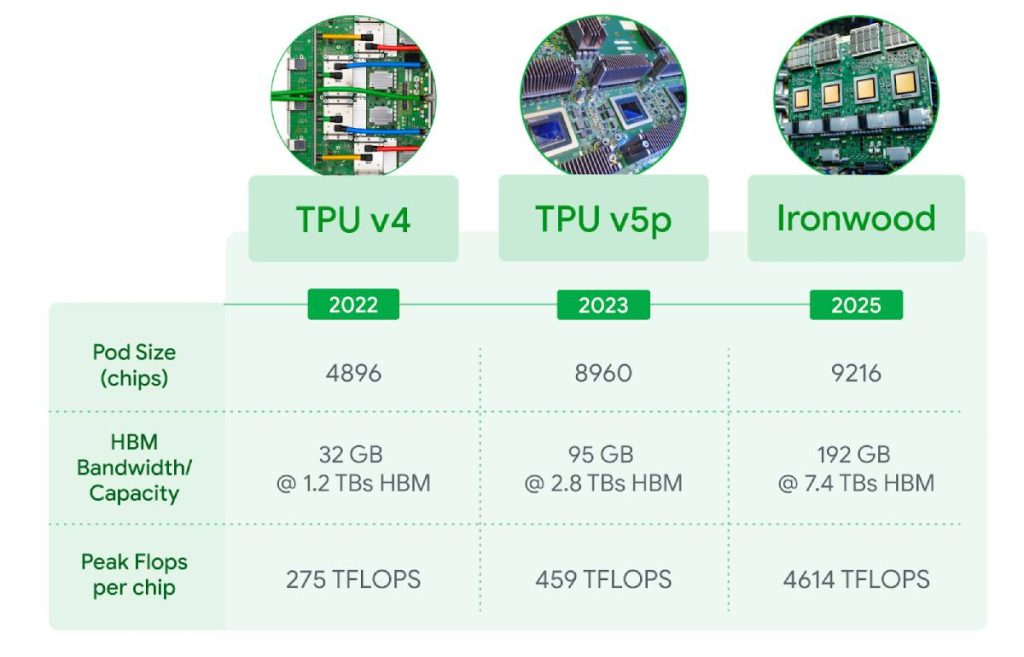
Compared to the previous generation Trillium, Ironwood shows significant improvements in memory capacity, computing power, and communication capabilities, laying a solid foundation for processing large-scale AI workloads.
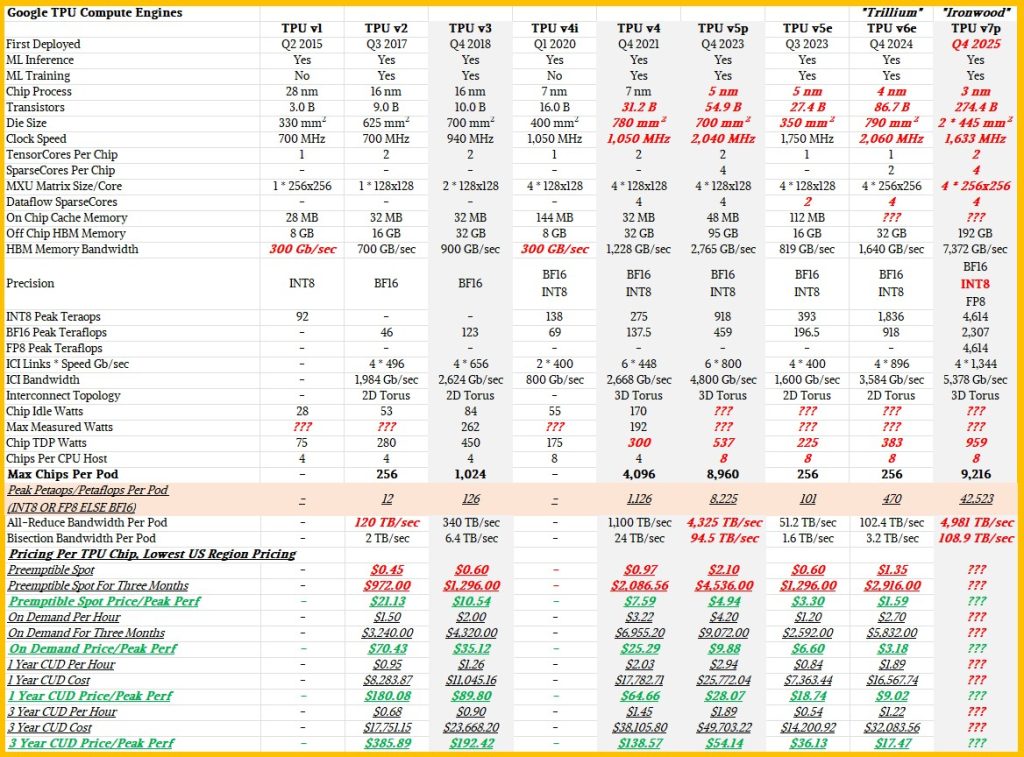
High-Bandwidth Memory (HBM)
Ironwood’s HBM capacity reaches 192GB, six times that of Trillium (32GB). This enhancement significantly reduces data transfer bottlenecks, enabling the chip to process larger models and datasets simultaneously.
For large language models (LLMs) or mixture of experts (MoE) models that require frequent memory access, Ironwood’s high-bandwidth memory is particularly crucial. Additionally, its HBM bandwidth of 7.2TBps is 4.5 times that of Trillium, ensuring high-speed data access and meeting the demands of modern AI tasks for memory-intensive computing.
Peak Computing Power
The single-chip peak performance of 4,614 TFLOPs makes Ironwood excel at executing large-scale tensor operations. This computing power level supports complex AI model training and inference tasks, such as ultra-large-scale LLMs or advanced inference applications requiring high-precision calculations. In contrast, Trillium’s single-chip computing power was only a fraction of its predecessor, making Ironwood’s improvement particularly remarkable.
Chip-to-Chip Interconnect (ICI) Bandwidth
Ironwood’s ICI bandwidth reaches 1.2Tbps, with bidirectional bandwidth 1.5 times that of Trillium. The high-speed ICI network ensures low-latency communication between chips, allowing multiple TPUs to work together efficiently. This design is especially suitable for ultra-large-scale clusters, such as the 9,216-chip TPU Pod configuration, which can fully leverage the total computing power of 42.5 Exaflops.
Energy Efficiency Innovations
Against the backdrop of surging global demand for AI computing power, energy efficiency has become a core consideration in AI chip design.
- Ironwood’s performance per watt is twice that of Trillium, with overall energy efficiency approaching 30 times that of the first cloud TPU from 2018, thanks to Google’s innovations in chip design and cooling technology.
- Through optimized architectural design, Ironwood minimizes energy consumption while maintaining high-performance output.
- In today’s environment of increasingly strained data center power supplies, this feature provides customers with a more economical and efficient AI computing solution. For example, when processing AI tasks of the same scale, Ironwood’s power consumption is only half that of Trillium, significantly reducing operational costs.
- To address the challenge of high power density, Ironwood employs advanced liquid cooling solutions. Compared to traditional air cooling, liquid cooling technology can maintain up to twice the performance stability, ensuring efficient operation of the chips under continuous high loads.
This design not only extends hardware lifespan but also supports reliable operation of ultra-large-scale clusters, such as the 9,216-chip TPU Pod, which approaches 10 megawatts in power.
Software Enhancements
Ironwood introduces enhanced versions of SparseCore and Google’s in-house Pathways software stack, further expanding its applicability across diverse AI tasks.
- SparseCore is a specialized accelerator designed for processing ultra-large embedding tasks, such as sparse matrix operations in advanced ranking and recommendation systems.
- Ironwood’s SparseCore has been expanded compared to the previous generation, supporting a wider range of workloads, including financial modeling and scientific computing. By accelerating sparse operations, SparseCore significantly enhances Ironwood’s efficiency in specific scenarios.
- Pathways is a machine learning runtime developed by Google DeepMind that supports efficient distributed computing across multiple TPU chips.
- Through Pathways, developers can easily leverage the combined computing power of thousands or even tens of thousands of Ironwood chips, simplifying the deployment of ultra-large-scale AI models. The collaborative optimization of this software stack with Ironwood hardware ensures efficient allocation of computing resources and seamless execution of tasks.
Ironwood’s Performance Advantages and Application Scenarios
One of Ironwood’s most notable features is its performance improvement. Compared to the first-generation TPU from 2018, its inference performance has increased by 3,600 times, with efficiency improved by 29 times.
Compared to the previous generation Trillium, Ironwood’s energy efficiency has doubled, with significantly increased memory capacity and bandwidth. The highest configuration cluster of 9,216 chips can provide 42.5 Exaflops of computing power, far exceeding the 1.7 Exaflops of El Capitan, the world’s largest supercomputer.
The 4,614 TFLOPs computing power of a single Ironwood chip is already sufficient to handle complex AI tasks, while the 42.5 Exaflops total computing power of a 9,216-chip cluster is unprecedented.
In comparison, El Capitan’s 1.7 Exaflops seems modest. This computing advantage enables Ironwood to easily handle ultra-large-scale LLMs, MoE models, and other AI applications with high computational demands.
In today’s environment where AI computing power has become a scarce resource, Ironwood’s high-efficiency design is particularly important. Its performance per watt is twice that of Trillium, providing more computing power for the same power consumption. This feature not only reduces operating costs but also responds to the global call for green computing.
Application Scenarios
Ironwood’s design philosophy is to shift from “reactive” AI to “proactive” AI, enabling it to actively generate insights rather than merely passively responding to instructions. This paradigm shift expands Ironwood’s application scenarios.
- Ironwood’s high computing power and large memory make it an ideal platform for running LLMs. For example, Google’s Gemini 2.5 and other cutting-edge models can achieve efficient training and inference on Ironwood, supporting high-speed execution of natural language processing tasks.
- MoE models require powerful parallel computing capabilities due to their modular design. Ironwood’s ICI network and high-bandwidth memory can coordinate the computation of large-scale MoE models, improving model accuracy and response speed, suitable for scenarios requiring dynamic adjustments.
- In fields such as financial risk control and medical diagnostics, Ironwood supports real-time decision-making and prediction. Its powerful inference capabilities can quickly analyze complex datasets, generating high-precision insights and providing critical support for users.
- The enhanced SparseCore makes Ironwood excel at handling ultra-large embedding recommendation tasks. For example, in e-commerce or content platforms, Ironwood can improve the quality and speed of personalized recommendations.
Google has introduced two TPU Pod configurations through Ironwood (256 chips and 9,216 chips), providing customers with flexible AI computing resources. This strategic layout enhances Google Cloud’s competitiveness in the AI infrastructure domain.
Ironwood will be available through Google Cloud later this year, supporting diverse needs from small AI tasks to ultra-large-scale model training. The 256-chip configuration is suitable for small and medium-sized enterprises, while the 9,216-chip cluster is aimed at customers requiring extremely high computing power.
Google Cloud’s AI supercomputer architecture optimizes the integration of Ironwood with tools like Pathways, lowering the usage threshold for developers.
Through this ecosystem, Google not only provides hardware support but also creates a complete solution for AI innovation.

In closing
As Google’s seventh-generation TPU, Ironwood opens a new chapter in the AI “inference era” with its exceptional hardware specifications and innovative design. With 192GB of HBM capacity, 4,614 TFLOPs of single-chip computing power, and 42.5 Exaflops of cluster performance, it leads far ahead in computing power, memory, and communication capabilities.
The enhanced SparseCore and Pathways software stack further expand its range of applications, from LLMs to recommendation systems, financial and scientific computing, showcasing unparalleled flexibility. Most importantly, its energy efficiency twice that of Trillium and advanced liquid cooling technology provide a model for sustainable AI computing.